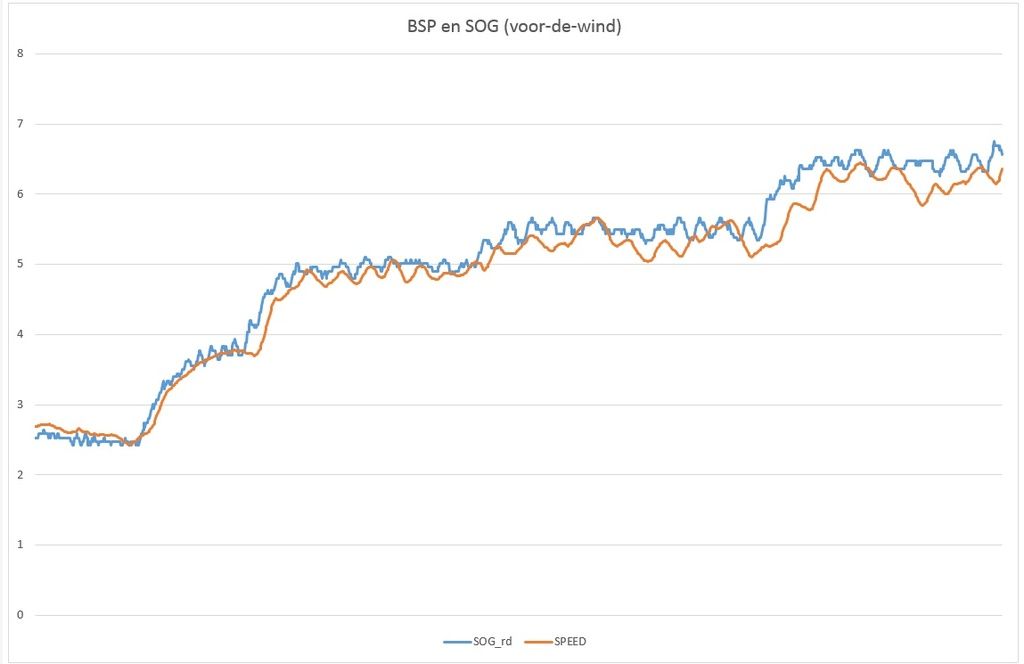
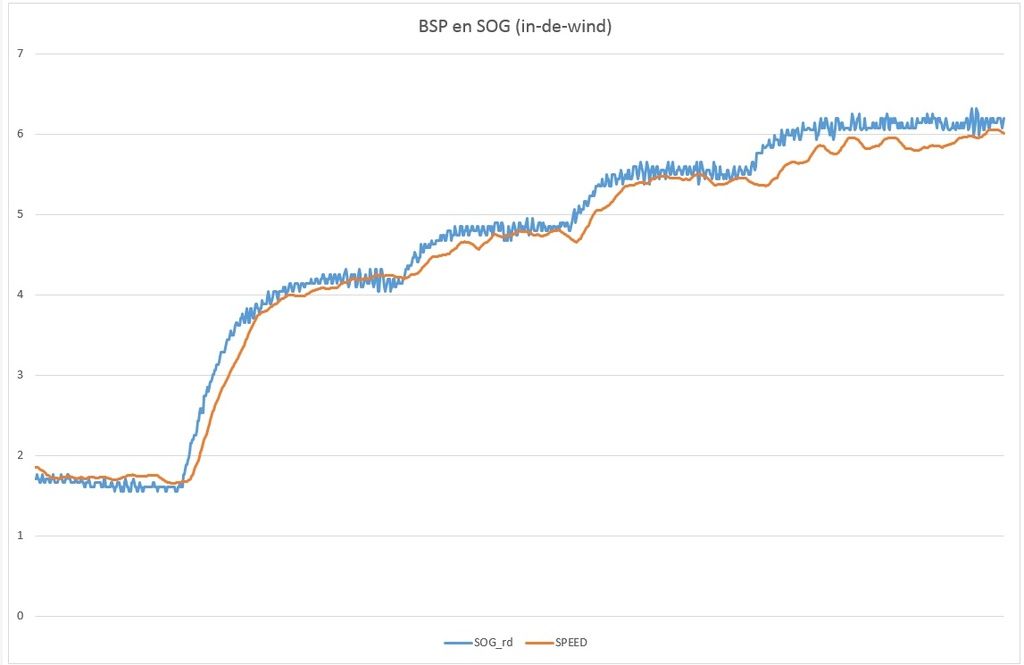
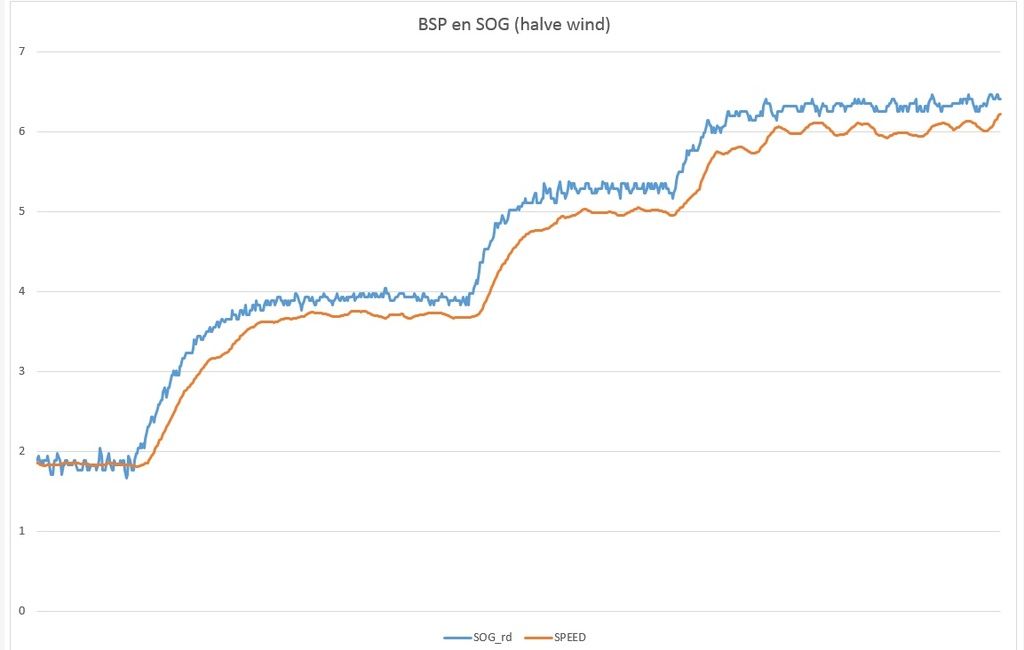
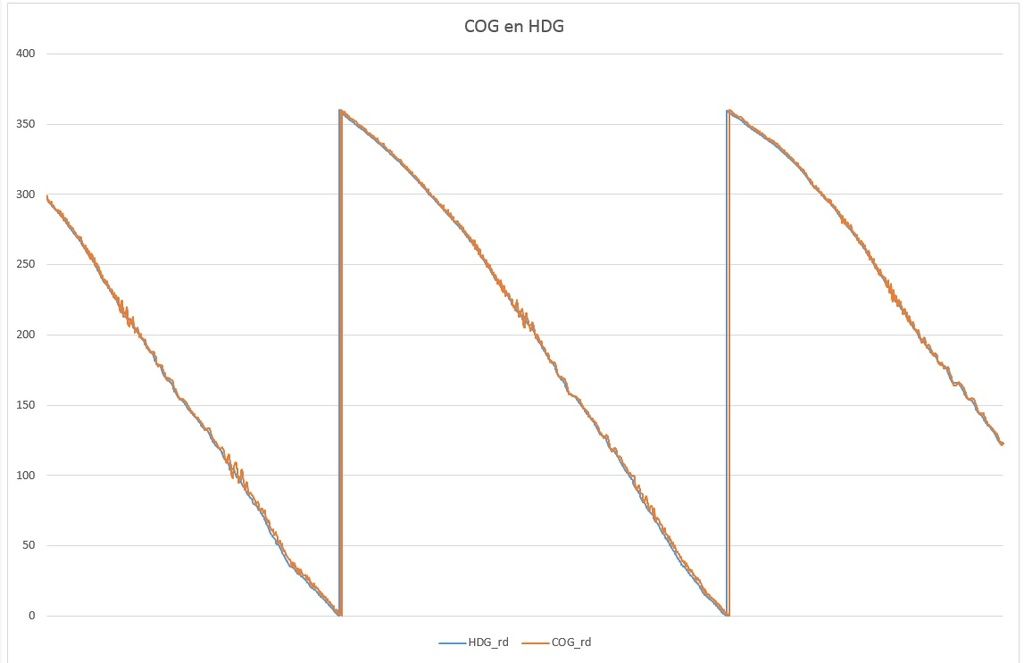
Vier opties uit te werken dus. Ik start met optie
2. Correctie in het tijdsdomein want daar weet ik het minst van en lijkt me interessant. Vooral dat "fase" gebeuren eens uitzoeken...
Idee bij optie 2 is dat er een FFT analyse mee loopt met een window gevuld met zo recent mogelijk gemeten waarden. De breedte van zo'n window is altijd 2
N samples, bv 256, 512, 1024 etc. Zo'n analyse kost veel processortijd en kan daarom niet real-time gebeuren. Je dient dus óf de weergave van de net binnengekomen data te vertragen (ongewenst) óf de FFT analyse gebeurt in een specifieke thread die op de achtergrond niets anders doet dan dat. Thread geeft dan een seintje aan de hoofdtaak dat er data uit een nieuwe analyse beschikbaar is. Tijdhuishouding dient zeer precies te zijn, omdat de signalen in zo'n window een vaste fase hebben en het hele window repeteert. Deze methode werkt het best indien het signaal stationair is, dwz het spectrum én de fasen van de componenten gelijk blijven. Deze randvoorwaarde zou in redelijke mate het geval kunnen zijn onder vaste condities met een bepaalde seastate.
Ik heb wat eenvoudige testsignalen aangemaakt en hier analyses op losgelaten die het belang van die fasen duidelijk maken.
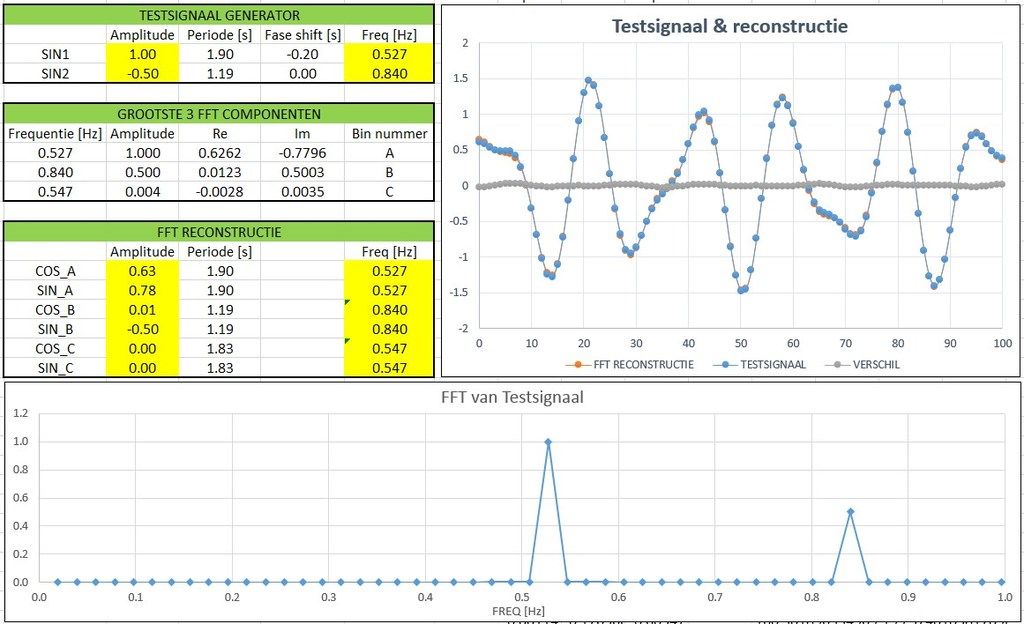
Hier een "ideaal" testsignaal van de som van 2 verschoven sinussen. De frequenties van beide componenten vallen precies in het midden van 2 bins uit het frequentiespectrum (0.537 Hz en 0.840 Hz). Dit is het blauwe signaal.
In het FFT spectrum kun je zien dat dit signaal slechts 2 componenten bevat (wat natuurlijk ook klopt - we hebben er slechts 2 ingestopt).
Het gereconstrueerde signaal ligt dan ook vrijwel perfect op het testsignaal. De grijze plot laat het verschil, de fout in de reproductie, zien en is zeer laag.
Het grappige is dat doordat de FFT een reëel en imaginair deel heeft, de fase ook bepaald is en dus gereconstrueerd kan worden. Deze fasen liggen vast in het window en herhalen zich dus één, twee, drie etc windowlengtes verderop. Alle door de FFT "gevangen" golflengtes/perioden passen preciés in het window.
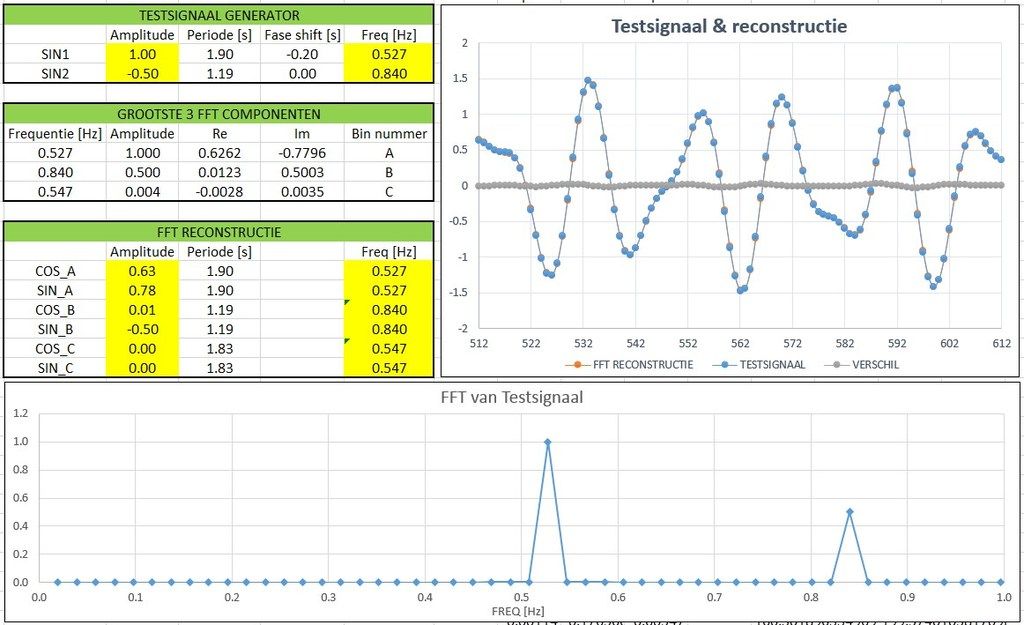
Kijk maar (tijdas 512 samples verschoven - precies hetzelfde plaatje):
Dit is belangrijk, omdat een verse meting, op het moment dat dit gepresenteerd wordt, gecorrigeerd dient te worden door de waarde op het corresponderende moment uit de gereconstrueerde FFT-tijdreeks. Onhandige zin is dit. Je dient dus precies te weten op welke plek uit het window je op ieder moment bent:
De plaatjes hierboven waren een schoolvoorbeeld, waarbij het testsignaal zich door slechts 2 componenten liet beschrijven (door 2 cosinussen in principe - die 2 sinussen komen erbij om de fases goed te krijgen).
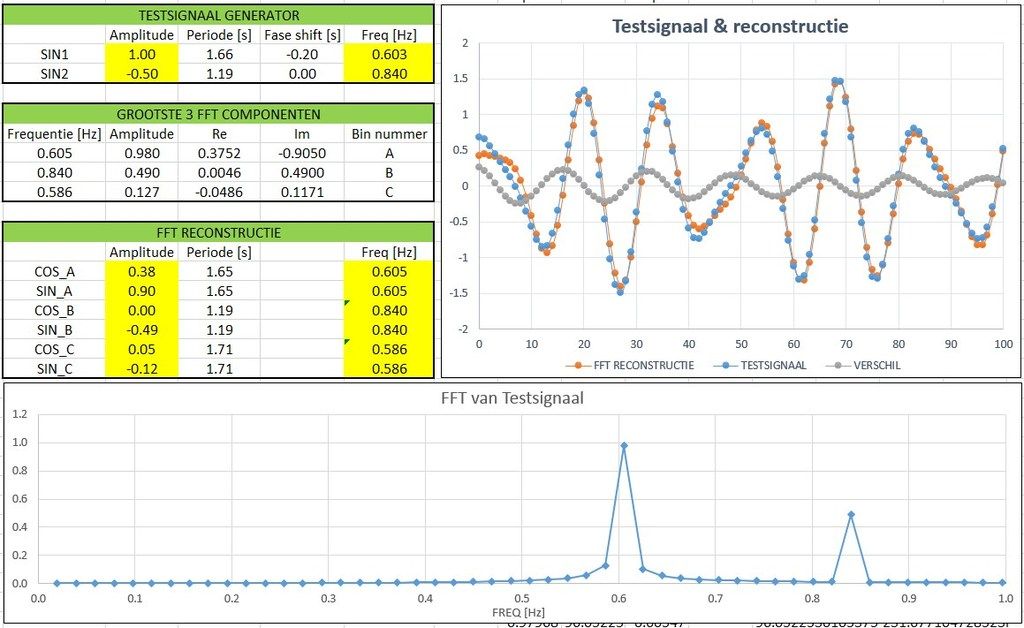
Nu iets lastiger en een heel klein beetje meer richting praktijk: de te corrigeren frequentie valt
niet samen met een (discrete) bin:
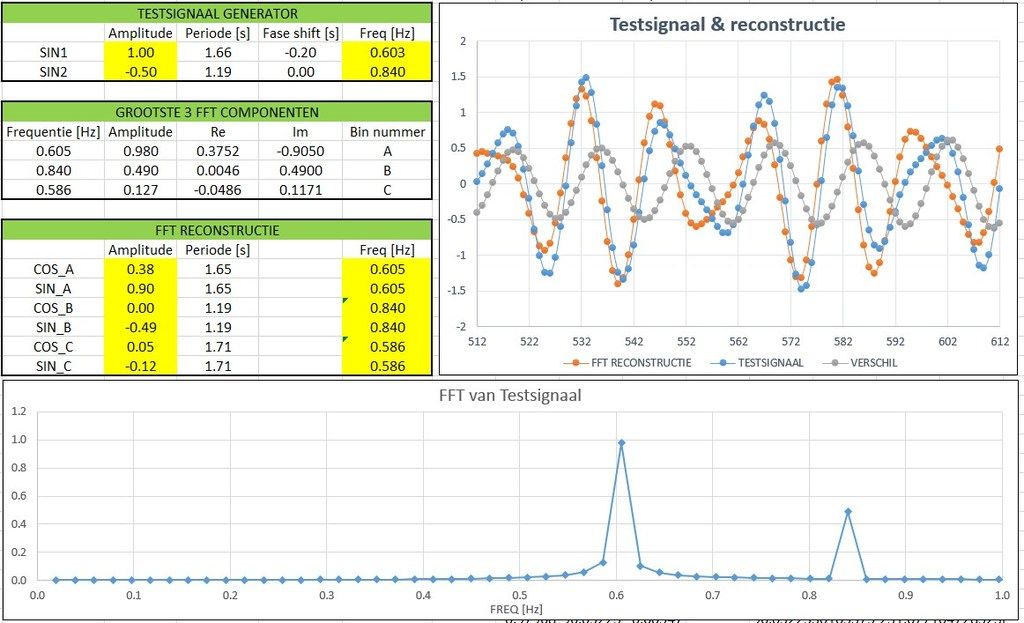
Hier zie je dat er al >3 componenten (reconstructie gebruikt nu alleen de 3 grootste componenten uit de FFT) nodig zijn om het signaal te reconstrueren. Let ook op de "versmeerde" bijdragen rond 0.6 Hz. Het signaal lijkt nog redelijk op het testsignaal, echter één window later lopen de fases steeds verder uit elkaar en wordt het al behoorlijk rommelig:
Doordat de perioden van het testsignaal en het gereconstrueerde signaal een fractie van elkaar verschillen, gaan deze steeds verder uit elkaar lopen.
Dat is ook inherent aan de discrete FFT: er kunnen slechts een beperkt aantal frequenties geïdentificeerd worden. Door (veel) meer componenten mee te nemen (die de gehele piek in het spectrum meenemen) zal het vast beter kunnen worden. Maar waar stop je dan?
Overige nadelen/risico's:
- Rekenintensief; analyse zal altijd achter lopen. Dit is niet erg indien het een zuiver stationaire periodieke verstoring betreft, maar dat zal in de praktijk nooit (lang) het geval zijn
- Kleine fase fouten stapelen zich op naar verloop van tijd: analyse zal continue uitgevoerd moeten worden om de huidige omstandigheden te kunnen "tracken";
- Sampling stabiliteit dient erg constant te zijn (zie 3Noreen's verhaal)
- Filtert slechts één frequentie (of zeer nauwe band) weg. Bij een licht variërende periode in de te filteren verstoring zit deze methode er vaker naast dan raak.
Ben nu hoogstens "bewust onbekwaam" op FFT gebied, dus tips en aandachtspunten zijn welkom.
Ik neig steeds meer naar optie
3. Adaptief filteren in het frequentiedomein. Heb daar al wat mee gespeeld maar wil dat nog verder uitwerken. Op échte data...